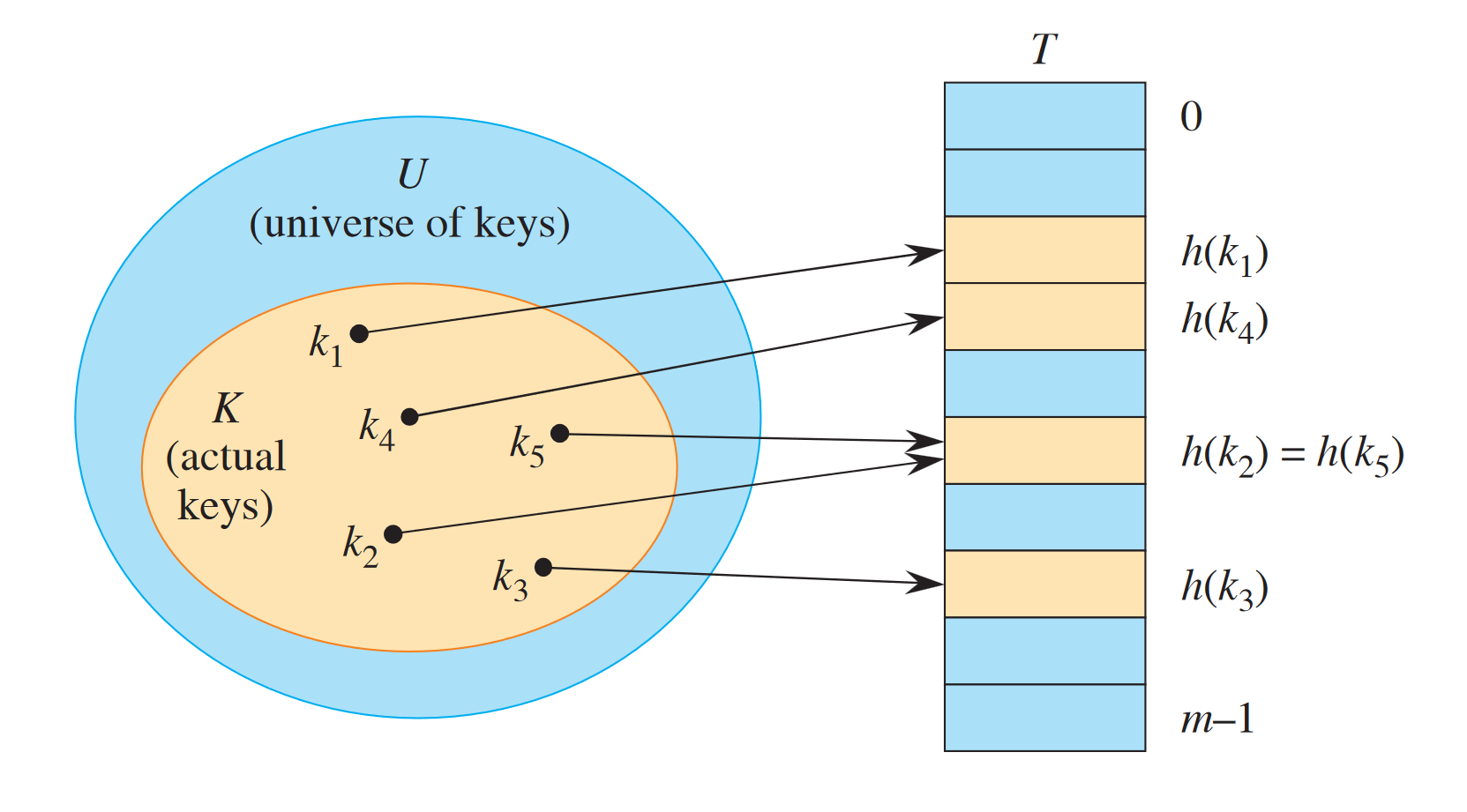
A hash table is a data structure that stores key-value pairs. Data is essentially stored in a very large array, at least 1.3 times as large as maximum number of elements to be stored. Each key will map to a unique index using a hash function .
Hash tables find uses in databases as well as in caching, where quick data retrieval is important. They’re fast: on average we see performance on basic operations like search, insert, and delete.
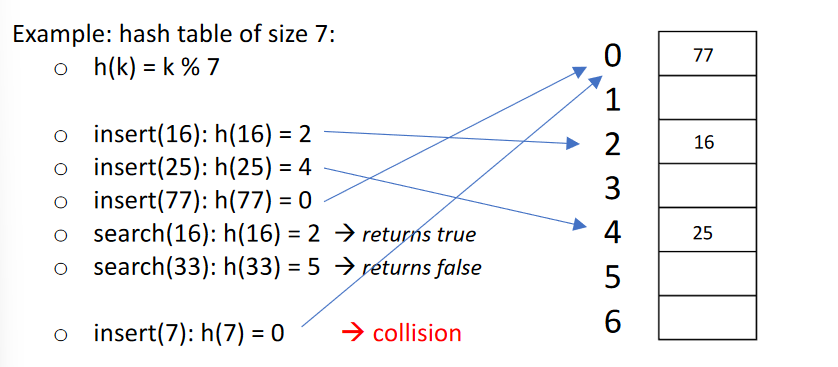
Good hash functions will map evenly across the array. For numerical values, an example of this is .1 We also need to deal with hash collisions where a hash function might return the same output for two different inputs. All hash functions deal with this, so that’s why hash tables are super large.
 As for some disadvantages:
As for some disadvantages:
- We need to know the size of the table ahead of time
- Requires a huge amount of space
- Table needs to be zeroed out at the beginning
- We can’t list elements in an ordered sequence
Time complexity
Hash tables are fast: on average we see performance on basic operations (search, insert, delete). The runtime of hash operations will depend on the number of probes required, where the number of probes is a function of the load factor.
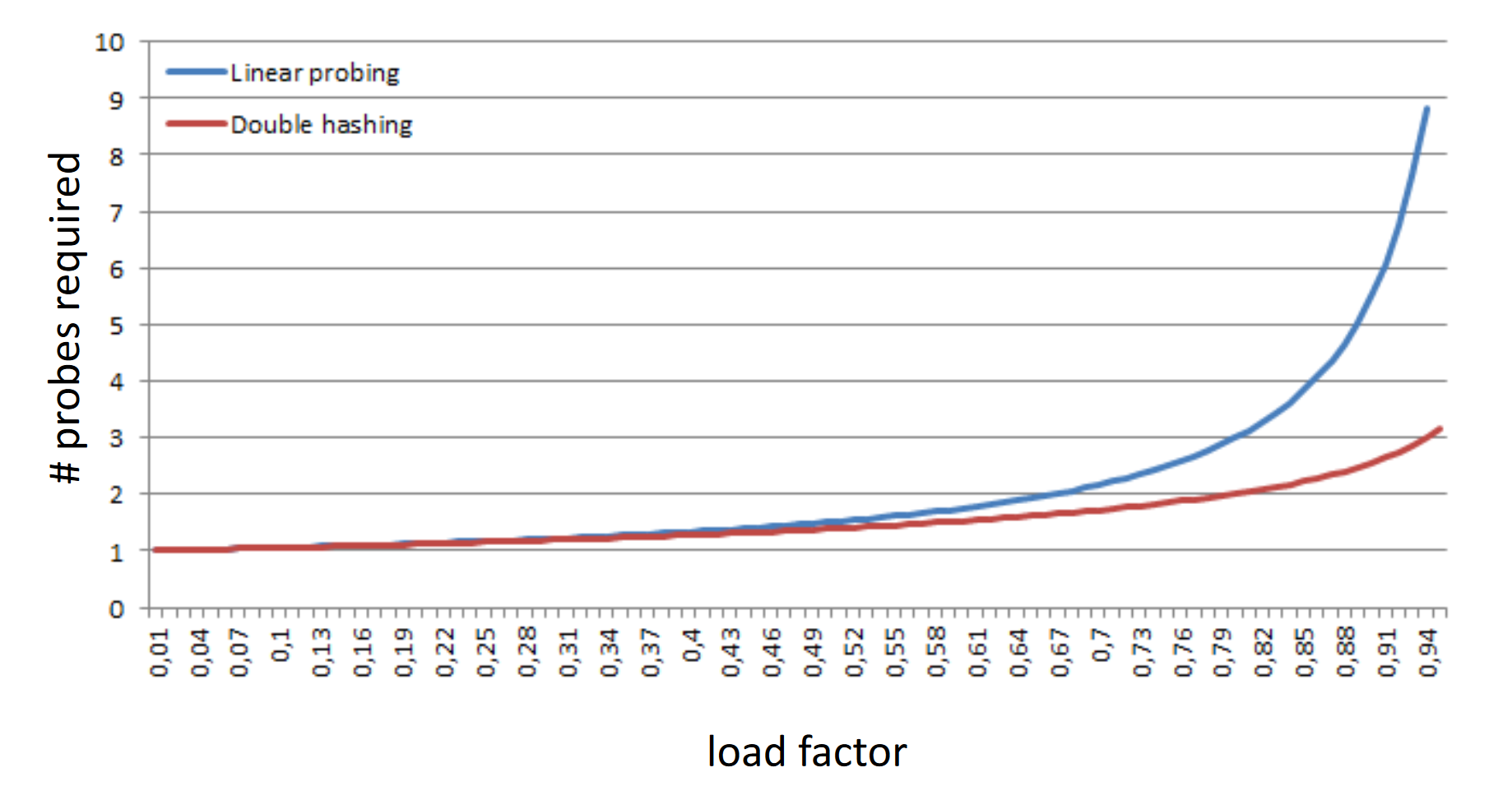
Basic operations
Insert operations should follow a hashing approach outlined in hash collisions. When we deal with deletes, we may run into problems.

Technical assessments
Many technical assessments (technical interviews, online assessments) have optimal or easy solutions that can be done with a hash map. These are ideal because:
- Storing the elements in the map has a space complexity of .
- Accessing elements has a complexity of . If we need to access every element, then it’s .
- Hash maps are unordered by default, so any questions that allow an unordered output can be solved with a set or hash map.
That’s simple enough! When do we not use a hash map?
- If the input is sorted — we should use a set-based solution.
- If the output needs to be in a particular order — then we use a vector.
Thread-safe tables
One simple way we can make a thread-safe concurrent hash table is via:
Language-specific
In C++
The C++ Standard Template Library contains the std::unordered_map<T, T> structure. This uses hashing with average access time. There’s also the std::map<T, T> structure, that is based on a red-black tree.
We can iterate through unordered maps with structured bindings (since C++17):
for (auto& [key, value]: table) Before C++17, we have to use:
for (auto& kv: table) {
auto key = kv.first;
auto value = kv.second;
}In Rust
Rust’s std hash map is provided as a HashMap<T, T> in the std::collections::HashMap. Its implementation is a thread-safe hash table originally designed by Google (as the hash brown hash map).
In Java
A single-threaded hash map is provided as a HashMap<T, T> in the java.util.HashMap library.
A thread-safe hash map is provided as ConcurrentHashMap<T, T> in the java.util.concurrent.ConcurrentHashMap library.
See also
Footnotes
-
From Prof Stumm’s lecture notes. ↩