Transformers are an architecture of deep learning models that are based on self-attention, where attention is modelled as a dictionary. It retrieves a value for a query based on a key . Values, queries, and keys are -dimensional embeddings.
Instead of retrieving a single value, it uses a soft retrieval that retrieves all values then computes their important with respect to query based on the similarity between the query and their keys:
Transformers are a seminal breakthrough in deep learning, and they’ve powered many advancements in deep natural language and computer vision models, especially in generative models like large language models.
The self-attention mechanism of transformers allow the model to attend to different parts of the input sequence simultaneously. This facilitates parallelism via vectorisation and CUDA. Transformers also facilitate long-range dependencies, and avoid any gradient problems — both benefits of transformers over RNNs.
Attention mechanism
There’s a few different steps:
- Input embeddings: the input sequence is embedded into a vector space.
- Self-attention: this embedded input is passed through a self-attention mechanism, which computes attention scores for each element in the sequence.
- Weighted sum: these attention scores are used to compute a weighted sum of the input embeddings, which produces a new sequence of vectors.
- Multi-head attention: this process is repeated multiple times in parallel, with different attention weights to capture different aspects of the input sequence.
- Output: we concatenate the outputs of the multi-head attention and pass it through a linear layer.
To compute the queries, keys, and values from the input embedding , we use:
Self-attention functions
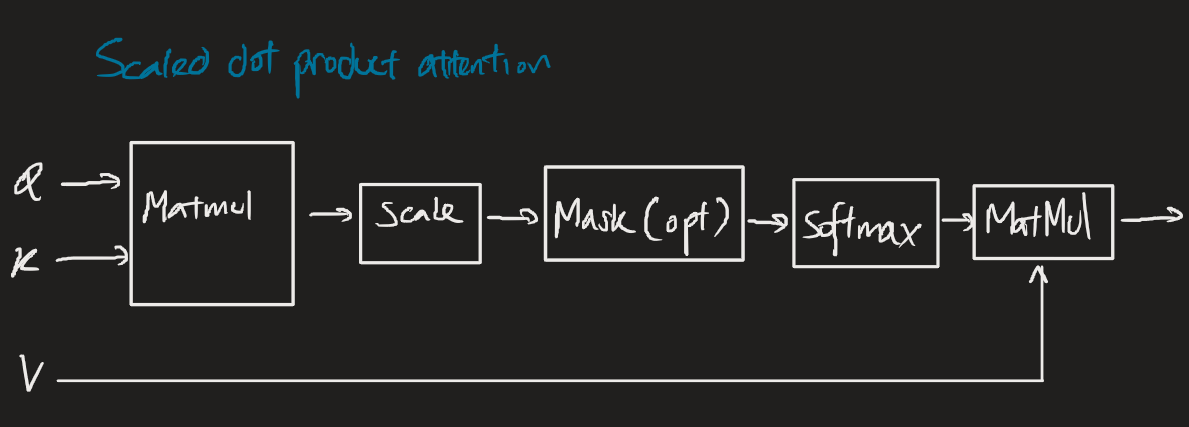
And we define self-attention (the scaled dot-product attention) in transformers as:
where , , are the query, key, value matrices. is the dimensionality of the input sequence.
- computes the multiplication of the query/key matrices to produce a matrix of attention scores.
- scales the attention scores to prevent large values from dominating the softmax function.
- The multiplication with computes the weighted sum of the value matrix, using the attention probabilities as weights.
- The output shape is the same as the input embedding matrix.
Multi-head attention improves the performance by dividing the representation space to subspaces, then runs parallel linear layers and attentions, then concatenates them back to form the original space.

Encoders
Encoder layers consist of a multi-head self-attention sub-layer, which is passed into a fully-connected feed-forward network. A residual connection around each sub-layer is followed by layer normalisation.
Transformers don’t have recurrent or convolutional layers so it doesn’t account for the order of sequence. We encode the position to use of the order, which allows for the model to easily learn to using relative positions.
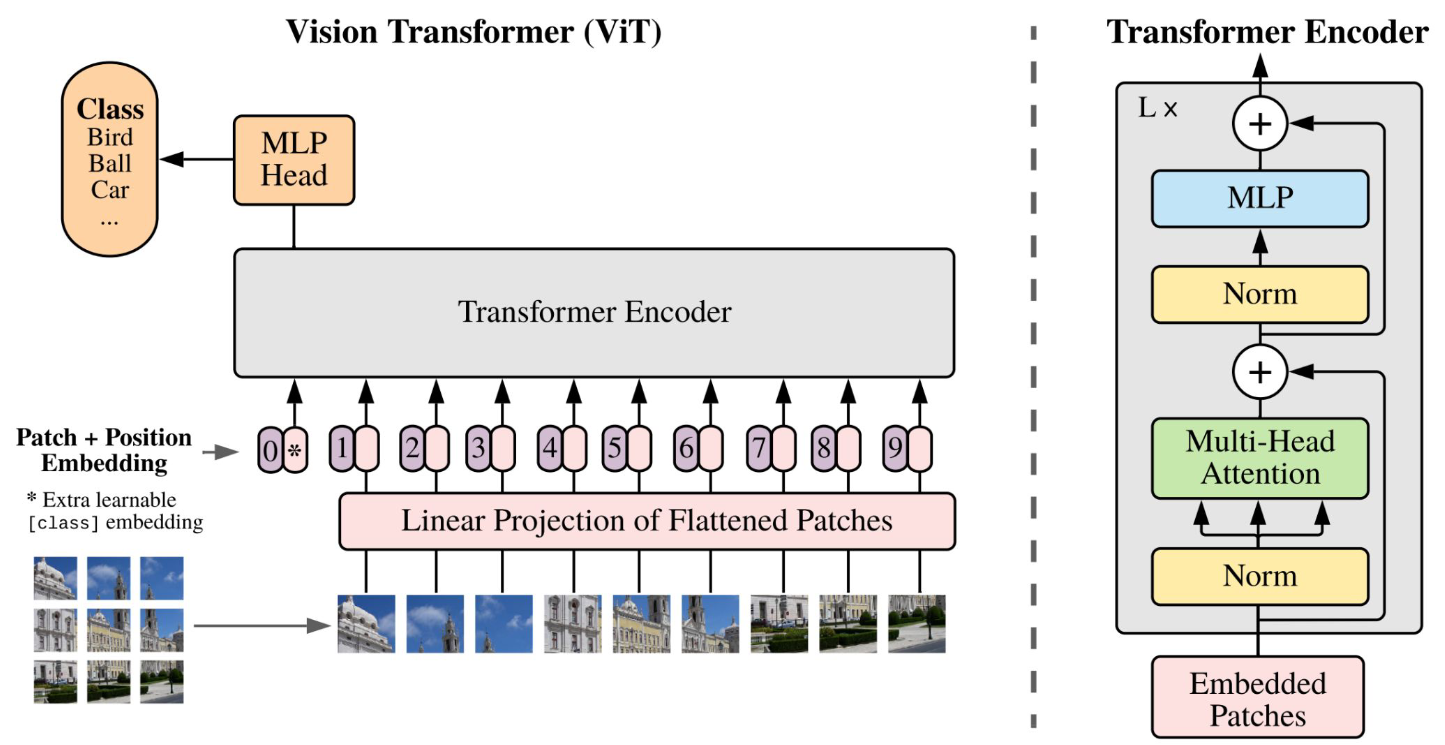
Vision transformers
Vision transformers (ViT) are transformer-based models for computer vision tasks. They achieve higher accuracies on large datasets compared to CNNs because of their higher modelling capacity, lower inductive biases, and global receptive fields.
Model complexity/size versus accuracy, CNNs are still on-par or better than ViTs.
In code
In PyTorch:
class TransformerEncoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(TransformerEncoder, self).__init__()
self.linear_q = nn.Linear(input_size, hidden_size)
self.linear_k = nn.Linear(input_size, hidden_size)
self.linear_v = nn.Linear(input_size, hidden_size)
self.linear_x = nn.Linear(input_size, hidden_size)
self.attention = nn.MultiheadAttention(hidden_size,
num_heads=4, batch_first=True)
self.fc = nn.Sequential(
nn.Linear(hidden_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, hidden_size))
self.norm = nn.LayerNorm(hidden_size)
def forward(self, x):
q, k, v = self.linear_q(x), self.linear_k(x), self.linear_v(x)
x = self.norm(self.linear_x(x) + self.attention(q, k, v))
x = self.norm(x + self.fc(x))
return xPyTorch also provides pre-trained transformer models for NLP tasks.
Resources
- Natural Language Processing with Transformers, by Lewis Tunstall, Leandro von Werra, and Thomas Wolf
- Attention Is All You Need, the breakthrough original 2017 paper from Google Brain
- Hands-On Generative AI with Transformers and Diffusion Models, by Omar Sanseviero, Pedro Cuenca, Apolinário Passos, and Jonathan Whitaker
See also
- Transformers, in electrical circuits