Bidirectional Encoder Representations from Transformers (BERT) describes a transformer-based large language model architecture. It uses a transformer model trained with two self-supervised tasks.
The first self-supervised task is masked word prediction. At random it replaces 15% of words with the [mask] token. Using the context of non-masked words, we can predict the original value of the [mask] token. The loss is computed on just the masked word.
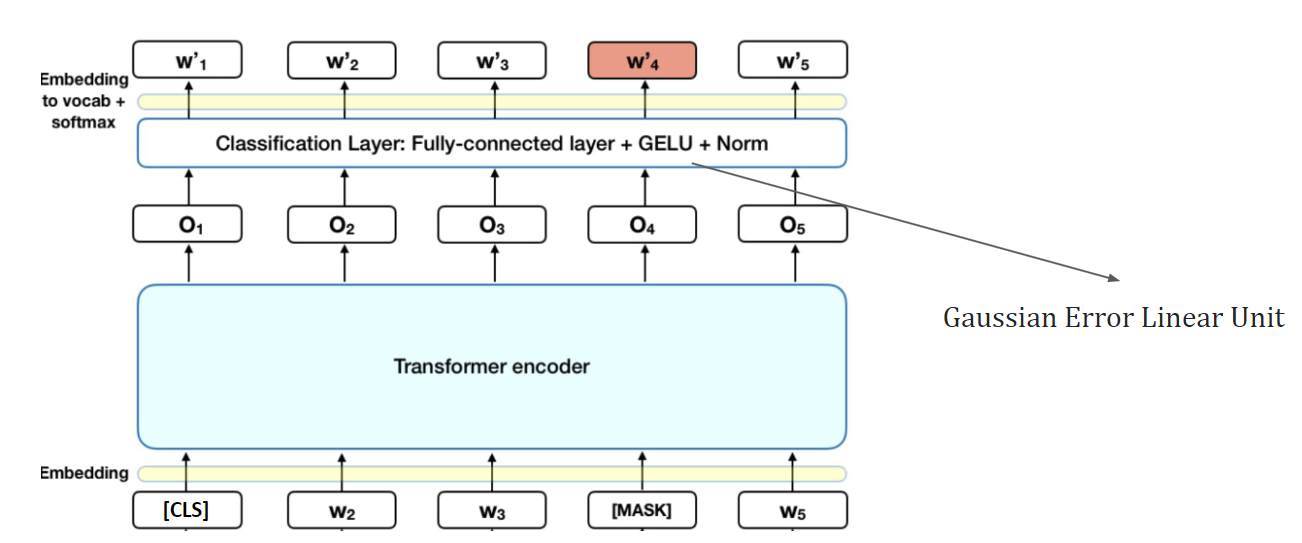
The second task is next sentence prediction. Given two sentences, we predict if they appear together. We want 50/50 positive/negative pairs of sentences ().
Transfer learning
One good thing is it shows great transfer learning capabilities, and it’s currently being used in Google search to represent user queries and documents.
It uses self-supervised training on large amounts of text, which allows it to grasp certain patterns in language, using a certain task (predicting the masked word). From here, we apply standard transfer learning steps by using supervised learning on a specific task with a labelled dataset.