ZooKeeper is a distributed coordination service. It implements a coordination kernel that allows applications to develop their own synchronisation primitives without changing the core of the service.
We could contrast this with Raft. Suppose we wanted to provide a distributed locking service. With ZooKeeper, we can compose it directly with ZooKeeper primitives. With Raft, there is no such thing — we’d have to list it as a log entry and verify it that way.
It’s designed to provide high performance: it allows multiple outstanding operations by a client, and reads are fast (albeit they may return stale data). It’s also designed to be reliable and easy to use.
Architecture
ZooKeeper state is maintained in memory. Each FS node is called a znode, and it stores some data that is read and written in its entirety. znodes may have children, which creates a hierarchical namespace, much like a regular filesystem. Each znode has a version number, which tracks how many writes occurred to a single znode and increments on each write.
There are two special types of znodes (on top of base znodes):
- Ephemeral: znode is deleted either explicitly (via the API), or automatically by ZooKeeper when the client session that created the znode fails.
- Sequence: appends a unique, monotonically increasing counter to the znode name.
The nodes consist of:
- The storage system is designed to be fault tolerant by using a replicated database. There’s a leader and many follower nodes, much like primary-backup. Each replica keeps a copy of the ZooKeeper state in memory.
- i.e., it achieves fault tolerance via storage replication. This is unlike Raft, which achieves fault tolerance with computation replication (all nodes’ code in each Raft instance has to be running).
- On start-up, servers elect a leader. If a leader fails, another is elected with a deterministic election protocol.
- Worker nodes operate on the replicated storage system. Clients will interact with the worker nodes instead of the storage system directly. A coordinator will
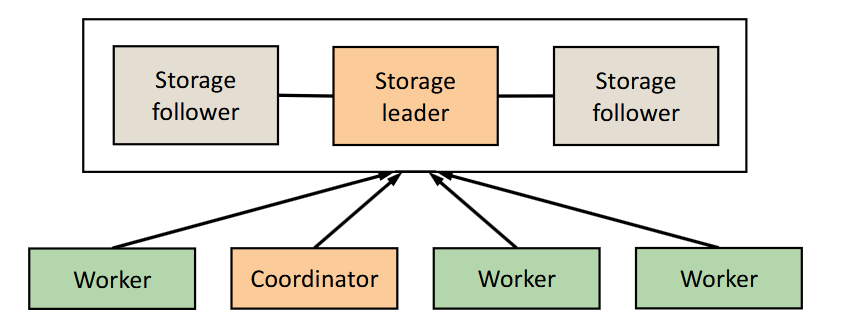
For good parallelism, clients will connect to different servers.
- To preserve the write linearisability, any write operations are forwarded by followers to the leader. The leader then replicates the writes using a total order broadcast.
- Any reads are executed on the replicas locally. This is quite efficient (no need to ping leader! Contrast with how Raft handles this), but the consequence is that if the follower lags behind the leader, then reads may return stale data.
API
The ZooKeeper API is again similar to a regular filesystem API. Operations take a path name to a znode. It uses a wait-free API that allows client requests to get a response without being blocked indefinitely by other clients’ operations or failures. i.e., slow and failed nodes cannot slow down fast ones, and there are no deadlocks.
Note the precise wording here. Wait-free doesn’t mean the client doesn’t wait — just that there is guaranteed progress.
The API is given below:
s = openSession()String create(path, data, acl, flags)void delete(path, expectedVersion)Stat setData(path, data, expectedVersion)(data, Stat) getData(path, watch)Stat exists(path, watch)String[] getChildren(path, watch)void sync(s)
The API has a few key properties:
- Operations are async, so many operations can be batched together.
- Clients will number messages and the ZooKeeper storage service will execute them in FIFO order.
- Completion notifications are delivered asynchronously, unlike RPCs.
- Batching state updates allows for fewer messages and disk writes.
- Only one concurrent create succeeds, i.e., exclusive file creation.
getDataandsetDatasupport atomic operations. The setter will fail if the data is modified sincegetData.- The sequence files allow operations to be ordered (like locking) across clients.
- Ephemeral files help cope with client session failure (group membership change, releasing locks, etc.).
- The API also supports watching, where a worker sets a watch flag on a specific znode and the storage system will notify the worker if something has changed. This avoids the cost incurred by polling.
After a client request:
- Any log writes to the ZooKeeper state is stored in a write-ahead log on disk (so that committed operations are not lost). Snapshots (much like Raft) are created and persisted for faster recovery.
- The leader will log the write, then send it to all followers (who then log it to their write-ahead log).
- When the leader has received an
ACKfrom a majority of servers, it commits the write. Leaders apply the write to the ZooKeeper state in memory then will inform followers. - Then followers will commit the write, apply it, and issue watch notifications, if any. And the replica in question will deliver a write response to the worker.
Coordination recipes
The API allows for coordination recipes to be used by applications to do synchronisation tasks. These are run on workers, which in turn interact with the storage system.
Consistency
ZooKeeper provides a consistency guarantee that is stronger than sequential consistency, but weaker than linearisability.
- Writes are linearisable. All clients will see the same order of writes, in real-time order.
- Reads/writes/other operations are executed in FIFO client order, i.e., a client’s operations will be executed in the order they’ve been sent.
The core implication: a client’s reads must wait for all of its previous writes to be executed. A client’s writes are applied in order. And a client will read another client ‘s writes in order.
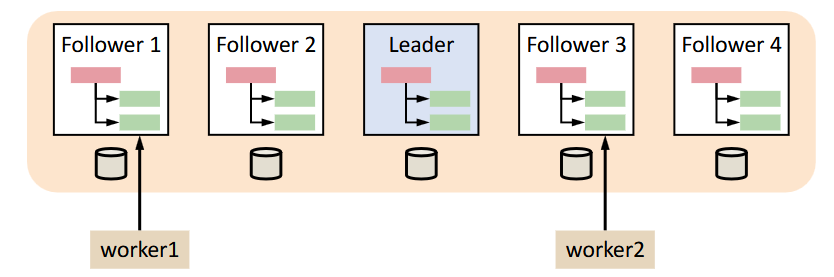
More concretely, suppose worker1 issues W1, R2, W3 to follower 1.
- Follower 1 forwards writes to the leader.
- Leader delivers writes to follower 1 in some order:
W, W, W1(where W are from other clients). - To enforce FIFO client order, follower 1 will perform R2 after it has seen W1, but before seeing W3.
To achieve this across replicas:
- ZK leader tags each state change with a unique ID
zkidin increasing total order. Each ZK replica will maintain the lastzkidthey’ve seen. - When a client connects to another replica, the replica delays responding to the client until replica’s
last_zxid >= client_last_zxid. This ensures that the replica’s view is always newer than the client’s view.
Failures
- coordinator failure
- ZK leader decides session has failed when no ZK server receives a keep-alive message from a session within a timeout
- ZK leader then will terminate session + delete ephemeral files
- when coordinator’s session is terminated, clients can use leader election recipe to elect a new coordinator
- what if a coordinator fails while updating ZK states