One-hot encoding is a general strategy to generate outputs (vectors, registers) based on what variable has a value of 1 (a “hot” variable). For variables, we want an -dimensional structure where the -th element of the -th vector corresponds to the -th variable.
In deep learning
The motivation behind one-hot encoding is that we want to learn an embedding of words. Contrast this with autoencoders that are used to learn an embedding space. We also need a way to convert words into numerical features without assuming a set order or precedence.
For an NLP task, we have a dimensional encoding that grows with the number of words. However, this is generally not a good approach for encoding text because they can’t express the similarity between different words (since cosine similarity for one-hot vectors is 0). This motivates the idea of word embeddings.
Finite state machines
For finite state machines, we want as many state variables and flip-flops as there are variables. For example, see the below. For the state table:
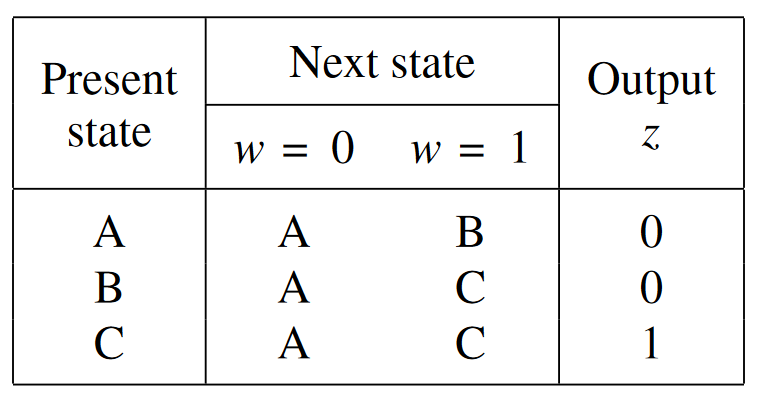 We get a one-hot state assignment of:
We get a one-hot state assignment of:
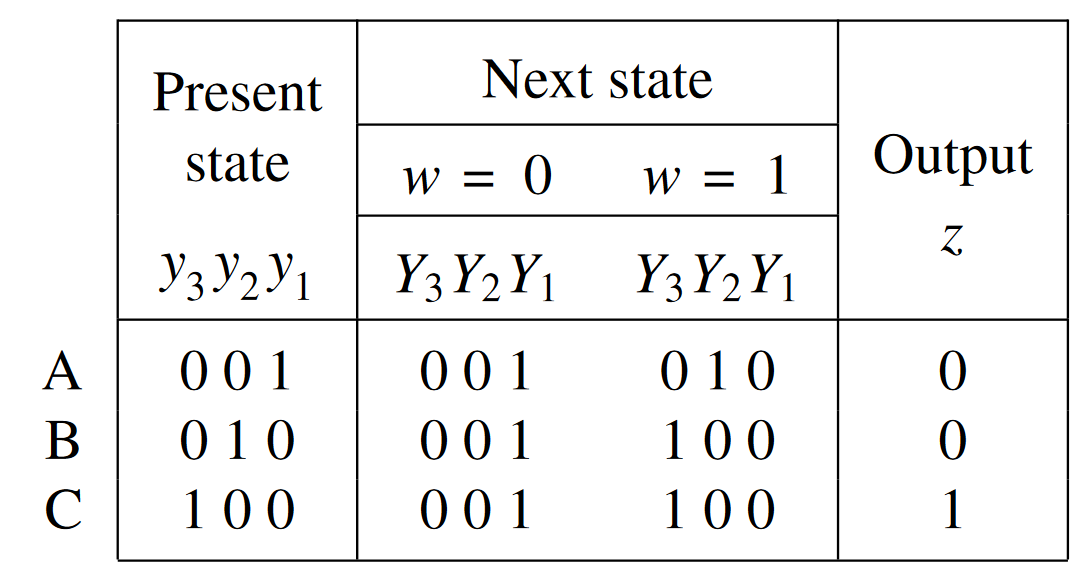 To write the next-state logic, we can look at the edges and arcs entering each state in the state diagram. Each edge corresponds to a product term in next-state logic for the state.
To write the next-state logic, we can look at the edges and arcs entering each state in the state diagram. Each edge corresponds to a product term in next-state logic for the state.