In statistical learning, autoencoders are unsupervised approaches to find efficient representations of input data that could be used to reconstruct the original input. Any typical deep learning architecture (MLPs, CNNs) can be modified for use for autoencoder use.
Autoencoders have two components: an encoder and a decoder. An encoder converts the inputs to an internal representation (with a dimensionality reduction). A decoder converts the internal representation to the outputs (i.e., it is a generative network).
Why a low-dimensional space? It forces the model to learn the most important/relevant features in the input data and drop the unimportant ones.
Deep autoencoders typically have multiple hidden layers that are symmetrical with respect to the central coding layers (i.e., the encoding path to the central coding layer is the opposite of the decoding path).
Applications
What can we do:
- Feature extraction
- Unsupervised pre-training
- Dimensionality reduction
- Generating new data
- Anomaly detection, since autoencoders are bad at reconstructing outliers
One way to check if an autoencoder is properly trained is to compare the inputs and outputs — note that perfect reconstruction doesn’t rule out overfitting. It’s also a good idea to apply noise to the inputs so that the autoencoder is able to separate the noise. This largely means the model is more robust to changes in the input.
For data generation, we can interpolate between different data points (of the same class) to generate a new image in between. For a random selection of different points in different classes, the latent space of the autoencoders can be disjoint and non-continuous (i.e., each class occupies a different subspace (like in t-SNE), so an intermediate representation just looks like nonsense).
This is fixed with variational autoencoders, which are intended to generate new data.
Image autoencoders are best done with convolutional architectures.
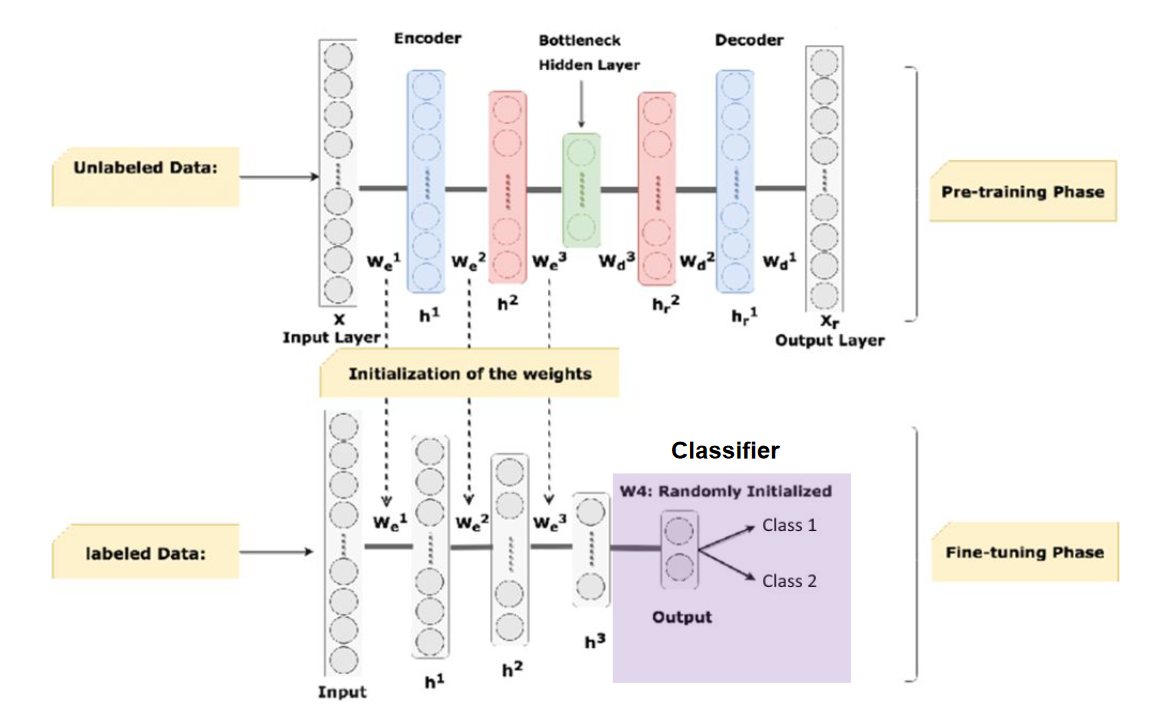
Pre-training
Just like how transfer learning can use pre-computed features to improve classification on certain tasks, we can also use autoencoders to pre-train on a large set of unlabelled data.
In code
Autoencoders can be specified in PyTorch, as usual. One notable change from a typical MLP architecture is the use of nn.Sequential() blocks. We specify the encoder and decoder as a sequential application of activation functions.
class AutoEncoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = nn.Sequential ( # insert activation functions here
nn.Linear(57, 34),
nn.ReLU(), # and so on
)
self.decoder = nn.Sequential(
# decoder has same functions in opposite order
)Note that any layers in the encoder must be identically mirrored in the decoder. Linear layers go in reverse (for example, if the encoder had a linear layer with 57, 34, the decoder must have an identical layer 34, 57.