Peer-to-peer (P2P) is a major application layer paradigm. Instead of a clean separation between clients and always-on servers, arbitrary end systems (peers) directly communicate. This means that end systems basically act as both clients (by requesting services from other peers) and as servers (by providing service to other peers).
This has the property of self-scalability, where new peers can bring new service capability and new service demands. Peers are generally intermittently connected and change IP addresses.
Quantitatively
In the client-server paradigm, the amount of delay is proportional to the number of users served. This means that the delay is largely bottlenecked either by the individual upload time (for clients, ) or the download time (F/d_\min).
D\ge \max \left(\frac{nF}{u_s}, \frac{F}{d_\min}\right)In the P2P paradigm, we see similar bottlenecks. But an additional bottleneck is the time it takes to distribute each file copy to each client. Both the demand and the supply increase linearly by , since each peer brings us service capacity.
D\ge \max \left(\frac{F}{u_s}, \frac{F}{d_\min}, \frac{nF}{u_s+\sum^n_{i=1}u_i}\right)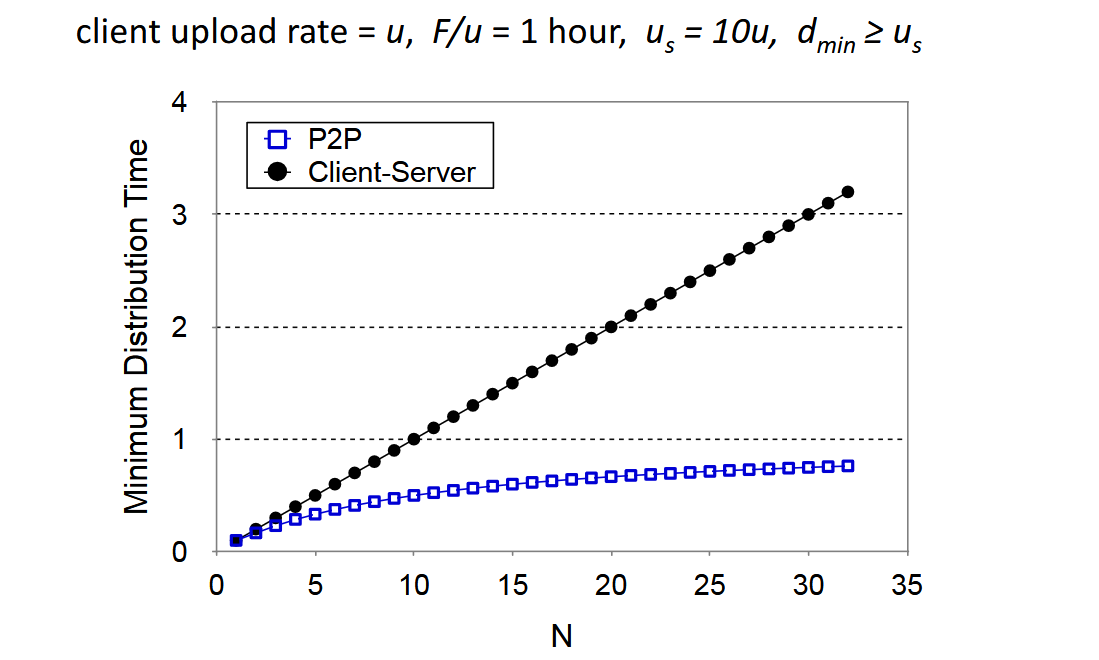
Mechanisms
An obvious question: how do we know which peer has the content, and how do we find out how to connect to them?
A centralised approach has a single server that stores the information of each peer. Each peer registers their address and an ID for the file. Then, a requesting peer contacts the server to know who to connect to. Then the peers directly connect. This means it’s easy to find content and quick to resolve the address. But there’s a central point of failure and clear performance bottlenecks at the server-side.
A fully distributed flood-based technique has one peer connected to a few other peers. To discover content, it can be found with a wave-based mechanism. With limited flooding, peers may not find the content. Flooding also isn’t scalable. At the initial state of the network, or when peers are discovering other peers for the first time, there are a set of bootstrap nodes that serve as initial contact points.
Distributed hash table
A distributed hash table (DHT) stores the content type (key) with an IP address (value). Peers can query the DHT with a key and also insert KV pairs. Segments of the DHT are split into multiple tables stored at different nodes in the network. We define the ID of the node as the last key in the node’s group. We also have pointers to the next section of the table (at a different node).
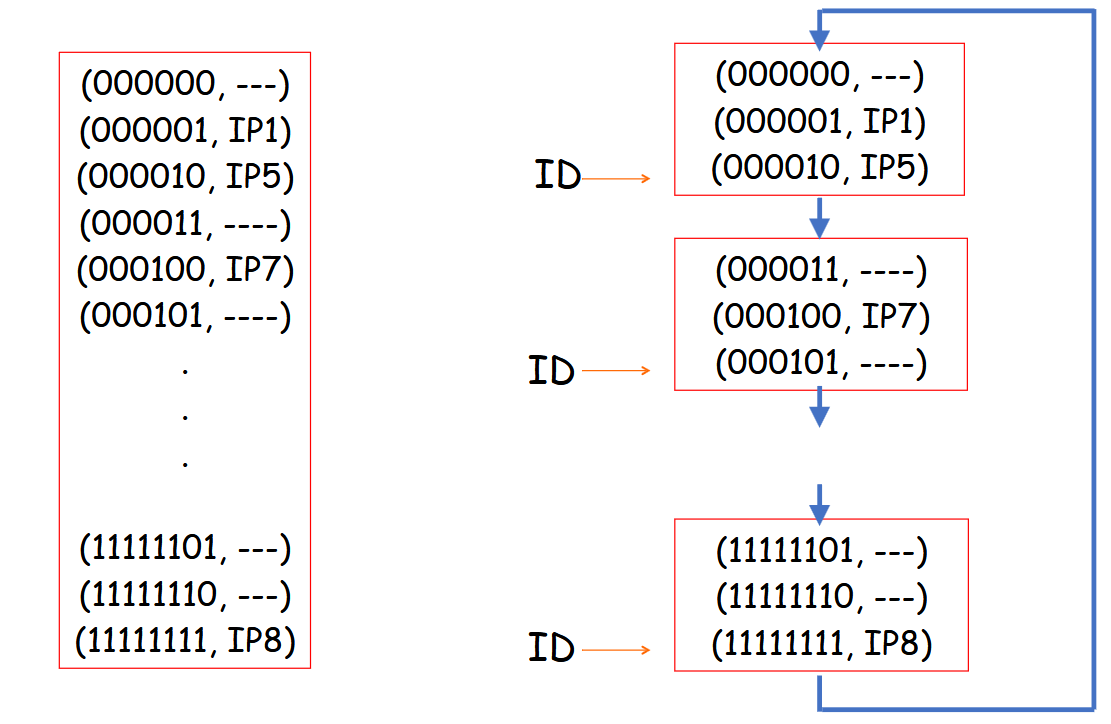
One mechanism this is achieved is with a circular DHT, where each peer is only aware of the immediate successor and predecessor. This means that resolving a query takes on average with peers. Then, a response given a DHT hit can be a direct connection.
With shortcuts, each peer also keeps track of a few peers ahead. It’s possible to design shortcuts such that we divide the search set each time, so we get performance instead.
Peer churn is when a node leaves the network. To handle peer churn, each peer has to know the IP addresses of its two next successors. Each peer periodically pings both successors to see if they’re still alive. The content of the DHT may be replicated or follow some other reliability mechanism.
contents of each DHT section — could be sent to other nodes upon leave?