Markov chains describe stochastic processes. They are based primarily on states and transitions, where the probability of the next state depends only on the current state. Markov chains are essentially a probabilistic variant of finite state automata.
Fundamentals
Suppose we have three discrete states. Suppose also there is some probability that the state of one body either remains the same or changes to the two other states.
Some handy definitions:
- Probability vector: where the entries are non-negative and sum to 1
- Stochastic matrix (also transition matrices): where each column are probability vectors; by *
When we apply some stochastic matrix to some distribution , our result describes the new distribution at state . An interesting application examines our understanding of diagonalization, allowing us to explore the population as time approaches infinity. Recall that for some diagonalisable matrix, we can express it in terms of some matrix , where its columns are eigenvectors and some diagonal matrix , where its elements are eigenvalues.
We apply it to our problem, using a handy theorem. If:
Then:
This is substantially more computationally efficient — as opposed to number of computations, we instead do three. We refer to our resulting population as the equilibrium distribution for .
Example
Say we have three lecture sections and students are free to attend different lecture sections, with a probability of either staying in the lecture session they currently attend, or two probabilities of attending a different lecture section.
If we begin with some population :
And some stochastic matrix that describes their behaviour after a state change is induced:
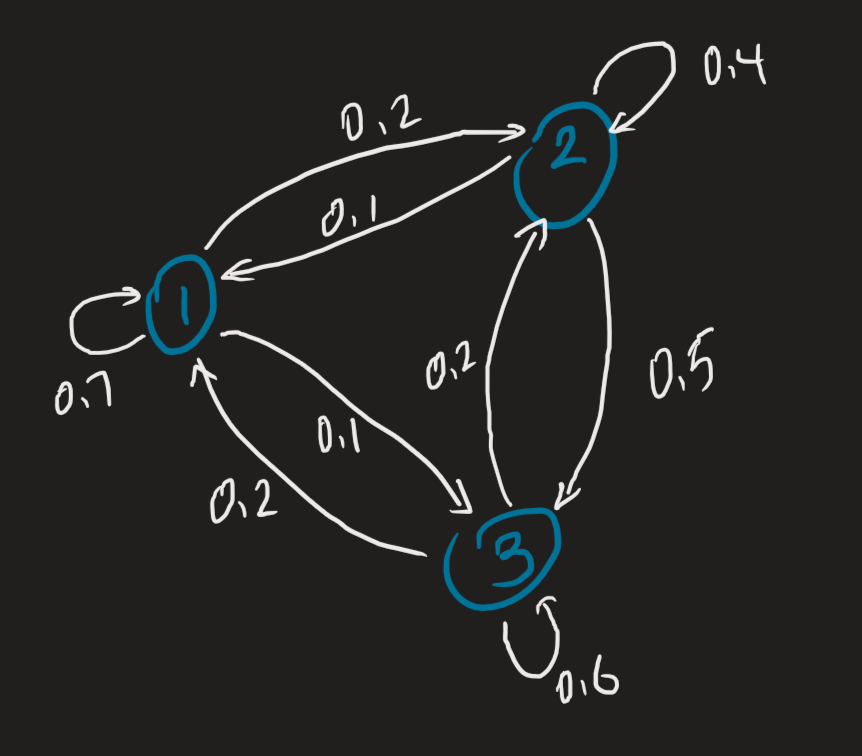
For the first column, 70% of students that are initially in the first lecture section will stay in that section. 20% will move to the second section, and 10% will move to the third section. We observe from above, that the vector describes the behaviour at . We also observe that encodes the change between and . Our understanding of diagonalization allows us to further extend this to find the number of students in each lecture section after an infinite amount of time.
Theorems
Equilibria for regular transition matrices Let be a stochastic matrix of size .
- There exists exactly one distribution vector such that , i.e., that is an eigenvector with eigenvalue 1. This is the equilibrium distribution for , denoted , which only has positive elements.
- If is any distribution vector in , then .
- is a matrix whose columns are all .