Caches are used within computer memory to function as a faster, smaller RAM unit close to the main memory. They function close to (or directly on) the processor, and are sometimes contained on the same integrated circuit chip. Computer systems usually have multiple levels of caches:
- The primary cache (level 1, L1 cache) is located on the processor chip. It’s small and has an access time comparable to the processor registers.
- The secondary cache (level 2, L2 cache) is a larger, but slower component between the primary cache and the rest of the memory.
- Other levels may also be included, including an L3 cache implemented with SRAM memory.
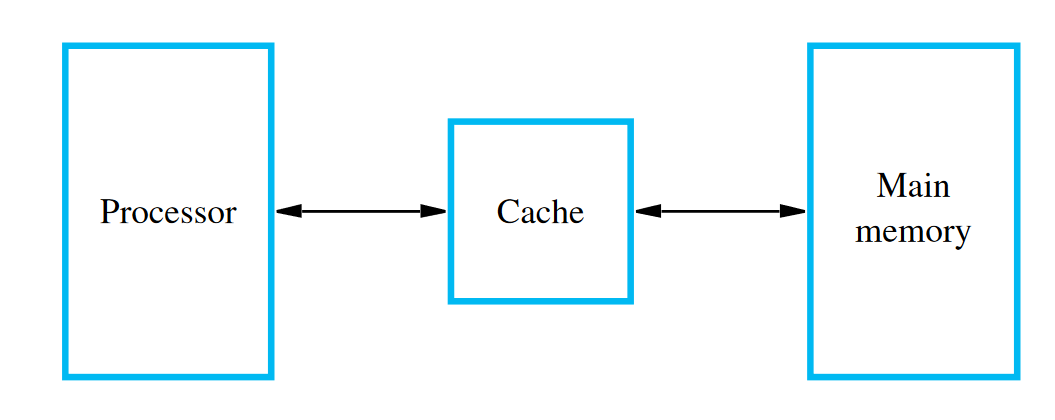 Caches are an important idea in systems design, whether in hardware, software, or networks. They’re foundational in the construction and design of the modern Internet.
Caches are an important idea in systems design, whether in hardware, software, or networks. They’re foundational in the construction and design of the modern Internet.
Sub-pages
Operations
Big memory blocks are slow (longer wires, more decoding circuitry) but for practical purposes we need large memories. If we accessed main memory each time we needed to, we’d need to wait multiple clock cycles before we can continue. Since smaller memory blocks are faster, we use a small, faster memory in between the processor and main memory. Many processors use separate caches for instructions and data.
The cache needs to keep the data of memory locations that the processor is currently using, which works well if the program uses a limited set of memory addresses at any one time. Programs that do this have the property of locality of reference (i.e., inside a loop or repeated call).
- Temporal locality: whenever an instruction or piece of data is first needed, it should be brought into the cache because it is likely to be needed again soon.
- Spatial locality: instead of fetching just one item, it may be useful to fetch several items located at adjacent addresses because they’re likely to be needed soon.
We have a general operation process for caches:
- The processor requests to read data at some address
A. - The cache looks at itself to see if it has a copy of the data at location
Ain the main memory.- If it doesn’t, we call this a cache miss. It slows things down because we need to grab it from main memory.
- Then, the cache requests that data from main memory. By spatial locality, we also request for data at adjacent addresses.
- If it does, we call this a cache hit. Then, we can send it to the processor quickly. We want cache hits to happen as much as we can.
- Modern caches have a cache hit rate of about 99%. This is the result of modern advancements in architecture.
- If it doesn’t, we call this a cache miss. It slows things down because we need to grab it from main memory.
Architecture
The cache is constructed out of four main components. One is where data is stored, where access is divided into lines of multiple words (similarly to how main memory is divided)1. There are also D, V, and Tag blocks. The Tag bits will store the main memory block (where the block is the same size as a cache block) number that the stored words belong to. The D bit (for “dirty”) is set to 1 if any word in the line is changed while the line already has data. The V bit (for “valid”) is set to 1 if the line stores valid data (useful after set-up).
How caches determine what main memory blocks should be saved and where is the process of mapping. A direct-mapped cache has one cache line for each block. An associative cache is if the block can go into more than one cache line. The cache runs a replacement algorithm to free up space in the cache for further use. This is trivial in a direct-mapped cache but in an associative cache this is more difficult.
The processor may want to write memory into the cache. If the cache changes the main memory right away, it’s called a write-through cache. This is a consistent approach but it’s slow if there are many writes to the same line. A write-back cache reduces the number of write operations by relying on the dirty bit. If there’s data with a dirty bit and the cache must run its replacement algorithm, the resulting evicted data is written back to the main memory before being replaced.
Analysis and optimisations
In general, we want to optimise our software in such a way that we minimise cache misses. Because of locality, if the memory is laid out in a certain way, we want to access it in a way that avoids rewrites.
Oftentimes, for big consecutive operations (big for loops, any kind of machine learning), the cache won’t be able to fit everything. Reordering things can avoid cache misses.
If a memory request gets a cache hit, let’s say it takes cycles (around 4 for modern processors). For a cache miss, let’s say it takes cycles (the miss penalty, around 300 in a modern processor). We can define the hit rate of a program that runs on a processor with cache:
With only one level of cache, the average access time (in number of cycles) experienced by the processor is given by:
Usually this results in a higher number of cycles depending on the parameter values.
Having multiple levels of caches ensure that there’s a higher hit rate. If the L1 cache has a miss, the L2 is supposed to act as a fallback — this means that its speed is generally less critical. For a 2-layered cache processor, the average access time is then:
If are both high (90% range), the number of misses in the L2 cache will reach less than one percent of all memory accesses. This means that the miss penalty and the speed of main memory is significantly less critical.
Footnotes
-
i.e., for a 32-bit system, we divide the main memory block into 4 bytes of 8 bits each. ↩