A prefix tree (also trie, digital tree) is a search tree where the data are strings, and the edges are defined by individual characters. This supports fast pattern matching for information retrieval.
We define a standard trie for a set of strings from an alphabet , such that no string in is a prefix of another string, as an ordered tree with the following properties:
- Each node of , except the root node, is labelled with a character of .
- The ordering of the children of an internal node of is determined by a canonical ordering of the alphabet .
- has external nodes (i.e., at the bottom of the tree), each associated with a string of , such that the concatenation of the node labels on the path from the root to an external node of yields the string of associated with .
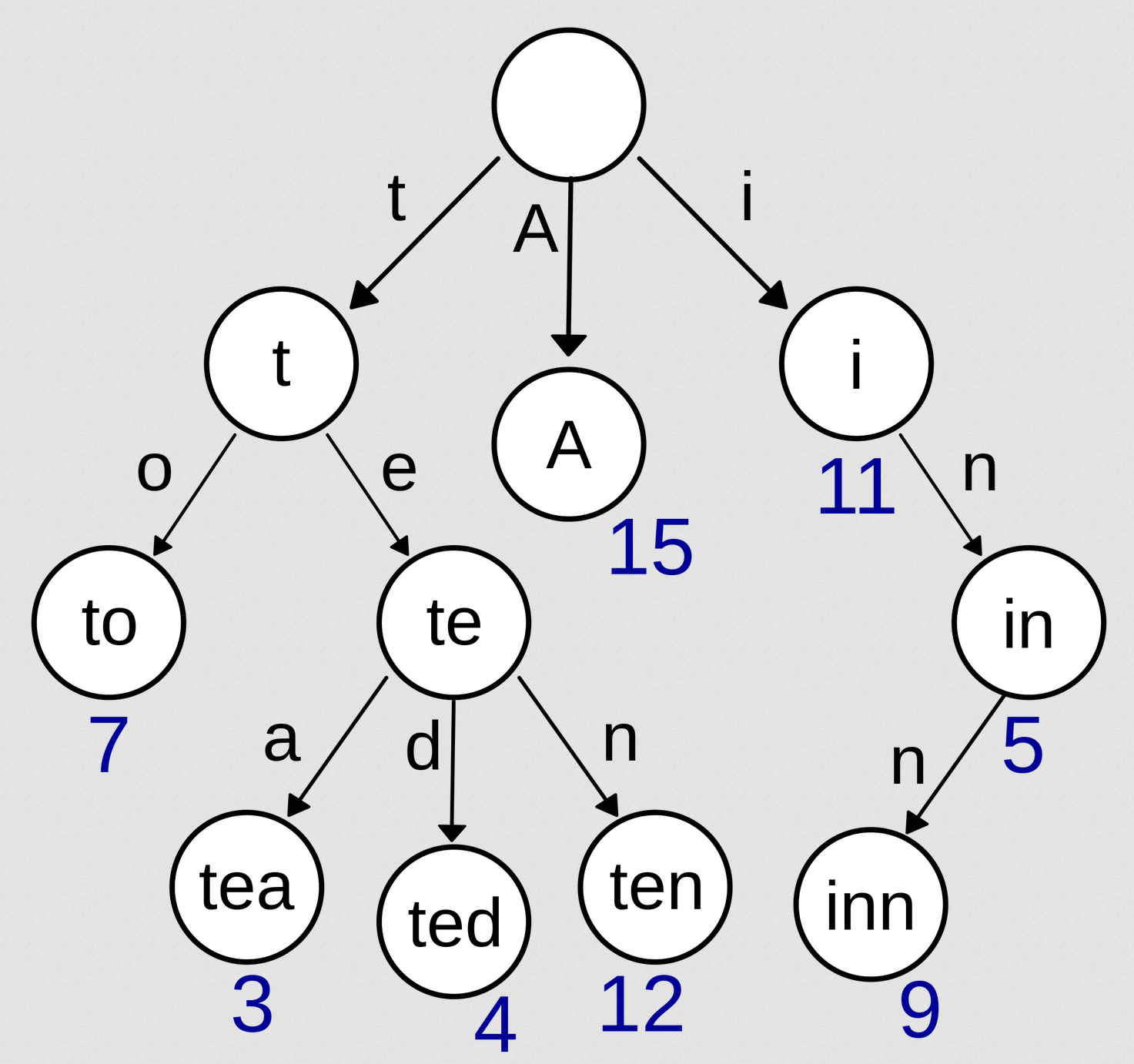 It’s easy to see that the time complexity for a string search of size in an alphabet of size will be , where is the look-up time complexity. Depending on the alphabet, this could be linear time (linked list), logarithmic time (tree set), or constant time (hash map/set, vector).
It’s easy to see that the time complexity for a string search of size in an alphabet of size will be , where is the look-up time complexity. Depending on the alphabet, this could be linear time (linked list), logarithmic time (tree set), or constant time (hash map/set, vector).
Then, the time complexity for insertion is .
Variation
Since standard tries potentially have many children with one node, this is an inefficient use of space. A compressed trie enforces that each internal node has at least two children, otherwise it holds the entire substring.
We say that a node of is redundant if has one child and is not the root. We also say that a chain of edges is redundant if is redundant for and and aren’t redundant.