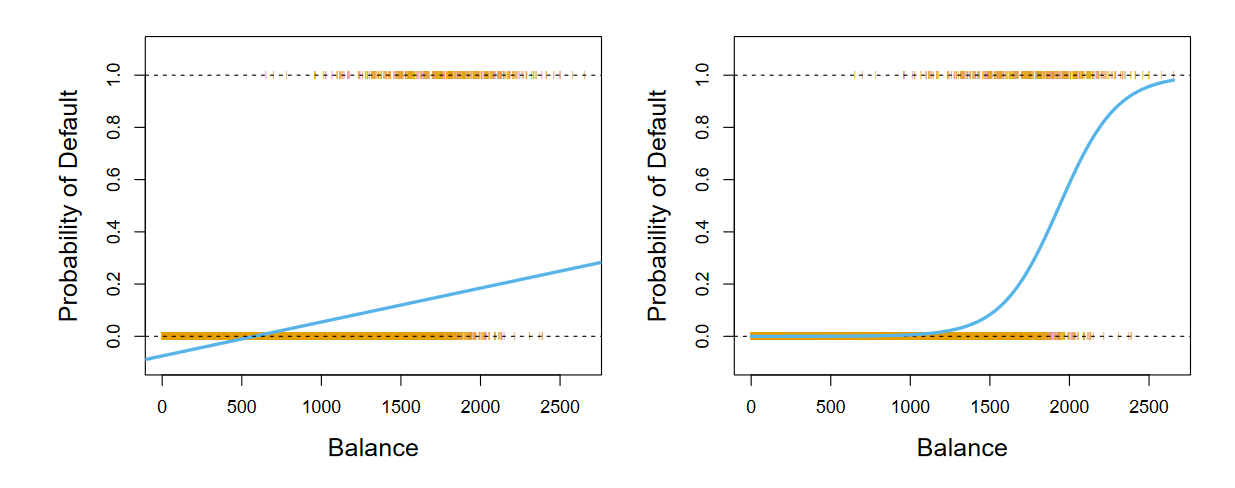
In statistical learning, logistic regression is a classification method. It is especially useful in binary qualitative problems, where we’re interested in finding outputs between 0 and 1 for all inputs. One of the problems of the binary case is that linear regression is a valid method, but we may get outputs outside of 0 and 1, which isn’t very helpful if we’re looking for a probability.
We use the logistic function, which produces an S-shaped curve. We use maximum likelihood to fit the curve, which is preferable to non-linear least squares.1
 The quantity in the logarithm below is called the odds, and is in the interval . High odds means high probabilities, and vice versa. The log odds or logit is:
The quantity in the logarithm below is called the odds, and is in the interval . High odds means high probabilities, and vice versa. The log odds or logit is:
We can observe that this is linear with respect to .
Downsides
Logistic regression may have substantial separation between the two classes. The estimates generated in MLE could also be unstable. If the distributions of the predictors are approximately normal in each class and the sample size is small, then another classification method is more suitable.
Footnotes
-
From Introduction to Statistical Learning, by James, Witten, Hastie, and Tibshirani ↩