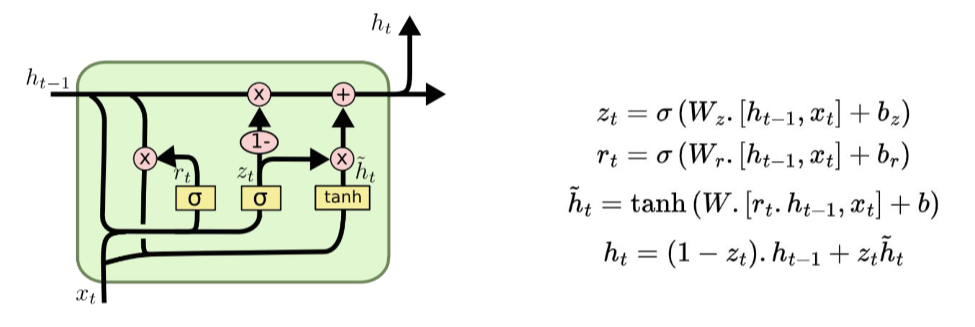
GRUs (gated recurrent unit) are an architectural variation of recurrent neural networks. They offer similar performance as LSTMs but are generally more efficient:
- They combine the forget and input gates into an update gate.
- And they merge the cell state and hidden state.
In code
A GRU layer can be specified with:
self.gru = nn.GRU(input_size=64,
hidden_size=256,
num_layers=4,
bidirection=True)