For larger programs, code is often split across multiple files. We want to separate the “interface” (declarations), which is needed to use the code, and its implementation (definitions).
We have declarations (of functions, objects) in header files and definitions in source files (i.e., in .cpp files). We use #include to include the header file in each file that wants to use those functions.
Why?
- It’s a better way to organise code.
- It makes it easier to collaborate — we can broadly split tasks file by file, programmer by programmer.
- Makes compilation faster — if we put large programs in one file, it’d take a couple minutes or more to compile. By splitting code, we have less that we have to re-compile each time. Linking is much faster than compilation.
- Each time we change a file, we don’t have to re-compile
A Make specifies instructions for how programs should be compiled.
Separate compilation
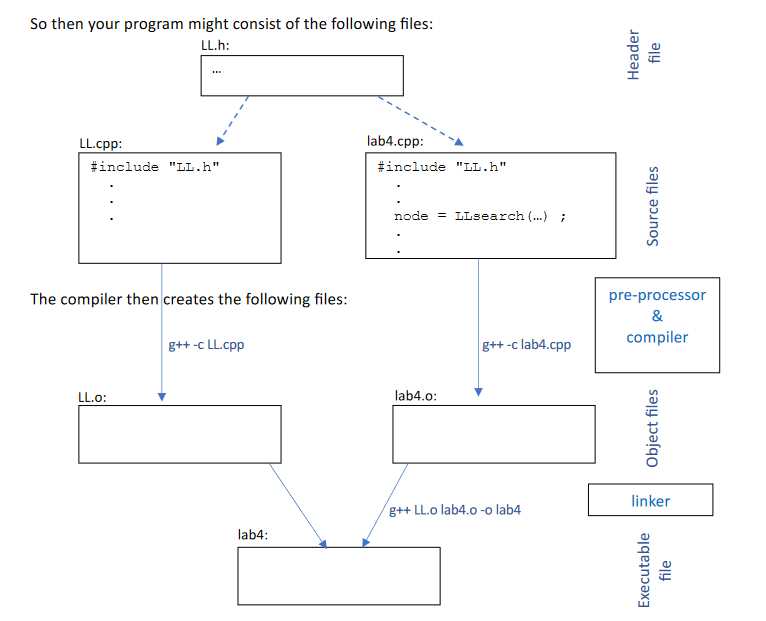
Source files have function implementations. Header files have function declarations. Object files have machine code with references to other variables or functions in other files, but cannot be executed.
In the command line, we can type g++ main.cpp print.cpp input.cpp -o main.exe, which specifies that:
- We use the G++ compiler.
- We compile
main.cpp. - We don’t compile an object file?
- We compile to an executable named
main.exe.
Let’s take an example, using linked lists. We need a type definition and some functions. We may want to put our type definition into a separate .h file to avoid copying it frequently. Our actual functions (for inserting, searching, etc.) can be put into a .cpp file.1
Considerations
When we #include, we textually add in the contents of that file. What this means is that duplicate function definitions are possible and do happen. This is why it’s generally bad practice to #include .cpp files. To avoid this problem with .h files, we use the #ifndef preprocessor.
Footnotes
-
From Prof. Stumm’s notes. ↩