The skipgram model predicts context words from the target word. These components need not be consecutive in the text, and can be skipped over or randomly selected from many documents.
A k-skip n-gram is an n-gram that can involve a skip operation of size or smaller. The neighbouring words are defined by the window size, which is a hyperparameter.
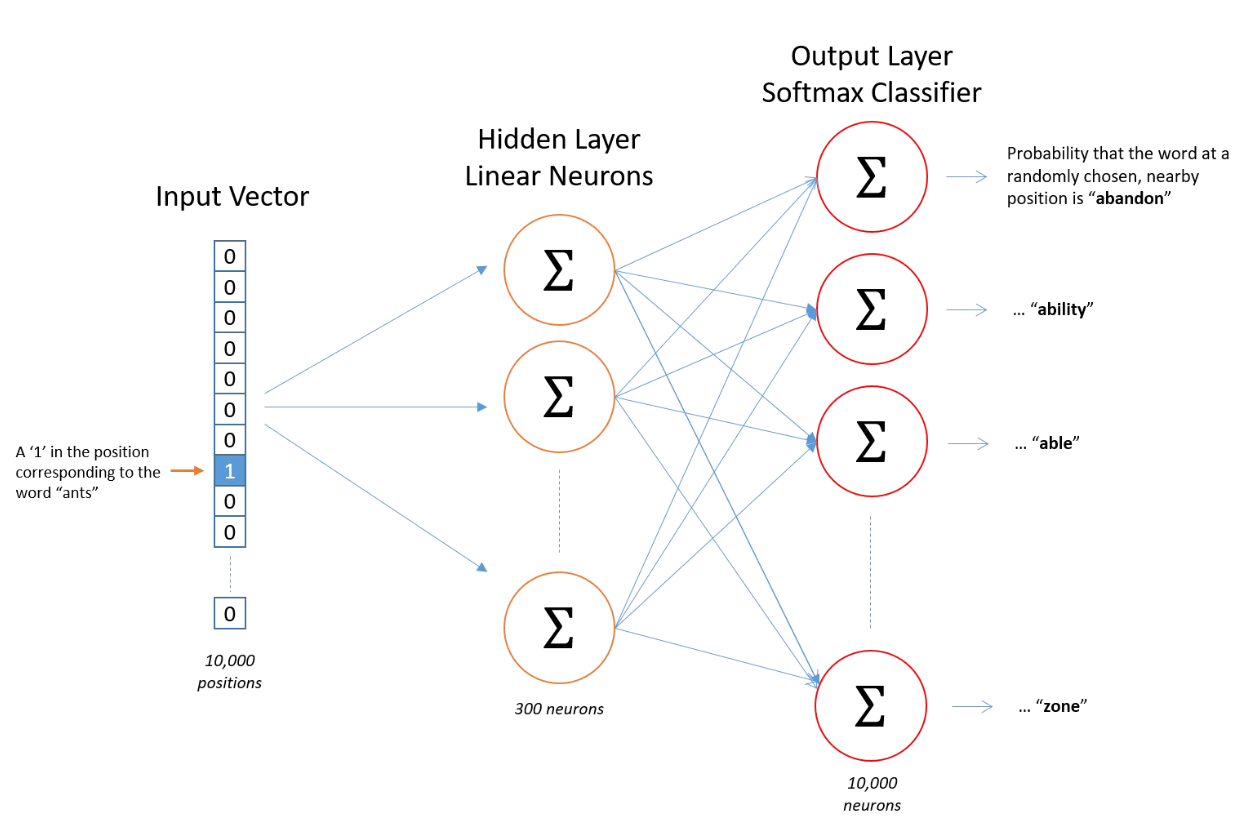 The output layer is only used for training. After the model is trained, we only keep the weights from the input to hidden layer. Then, words that have similar context words will be mapped to similar embeddings.
The output layer is only used for training. After the model is trained, we only keep the weights from the input to hidden layer. Then, words that have similar context words will be mapped to similar embeddings.
In general:
- It works best with small datasets.
- Has better semantic relationships (i.e.,
catanddog). - Better represents less frequent words.