The rectified linear unit (ReLU) is a popular activation function used in modern deep learning. It’s defined by:
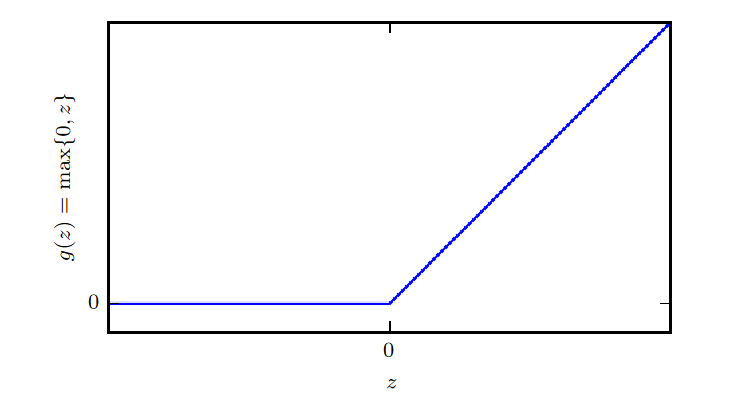 We set the derivative of ReLU at as 0, even though it’s discontinuous there. The derivative is functionally the unit step function:
We set the derivative of ReLU at as 0, even though it’s discontinuous there. The derivative is functionally the unit step function:
Motivation
As a rule of thumb, we should always just start with ReLU by default, instead of its variations. ReLU is a powerful activation function because it’s so computationally efficient.
ReLU’s derivatives are well-behaved, because it either vanishes or it lets the input through. This helps mitigate the vanishing gradient problem.
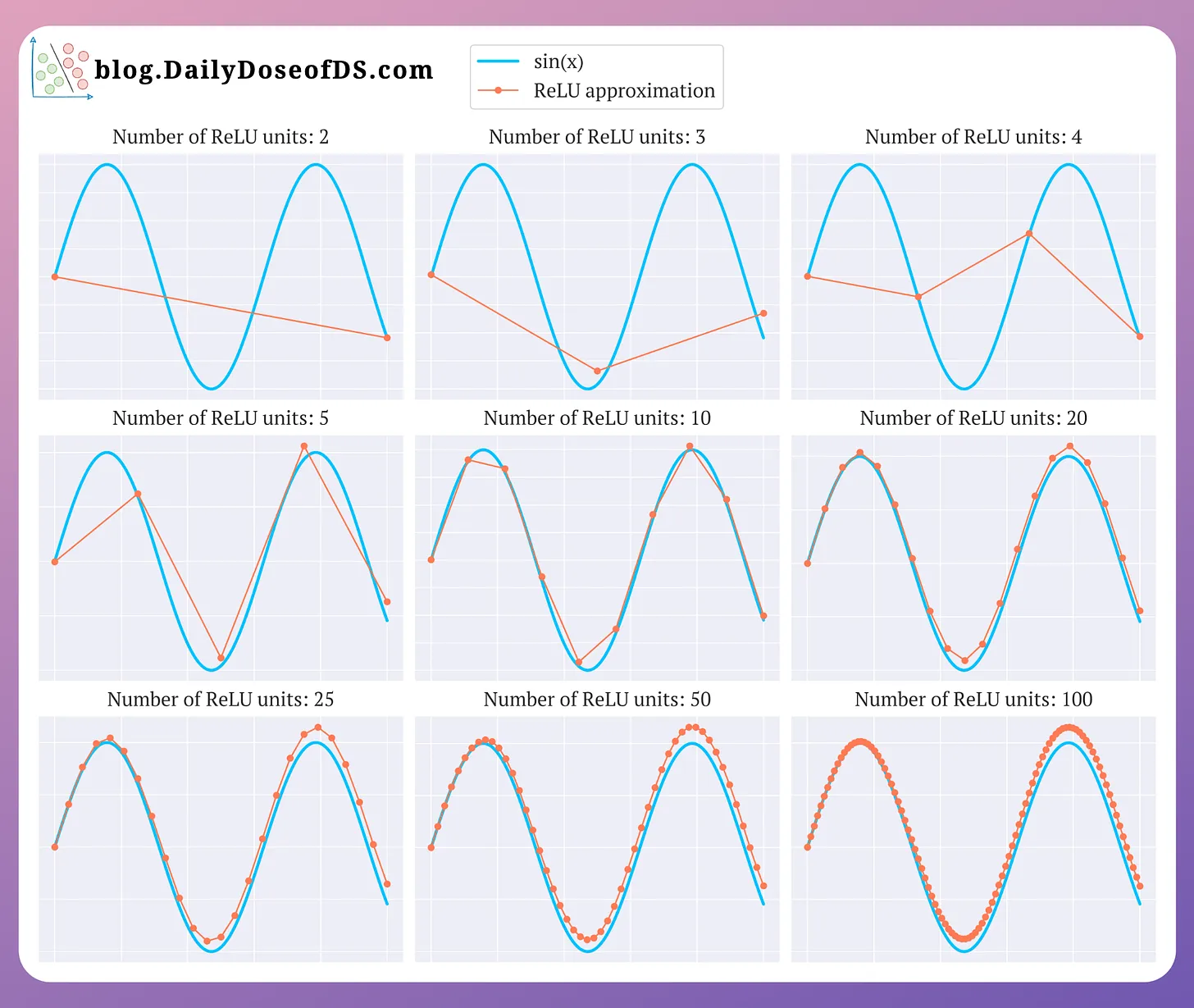
Multiple translated ReLU units offer piecewise linearity that approximates non-linearity. What this means is that with a sufficiently high number of ReLU units, we can approximate any non-linear function:
where are horizontal shifts. Approximating :1
Variations
Since ReLU’s derivative is discontinuous at , we’re motivated to explore continuous approximations of ReLU. We can approximate ReLU with continuous functions: SiLU and the softplus function.
The softplus function is defined by:
It’s useful in producing the parameter of a normal distribution.
In code
In PyTorch, we have:
y = torch.nn.relu(x)
y = torch.nn.functional.relu(x)Footnotes
-
From this great article by Avi Chawla at Daily Dose of Data Science. ↩