The learning rate () is a key property of gradient descent algorithms, usually a small constant. It determines the size of the step taken (usually by an optimiser) between each iteration of gradient descent. In machine learning terms:
Practically speaking: a larger learning rate means the parameters (weights) have bigger changes in each iteration. A high learning rate can be noisy and lead to overshooting, which is detrimental to training. It may converge, albeit in an erratic way. A low learning rate leads to small changes in each iteration, meaning a longer training time.
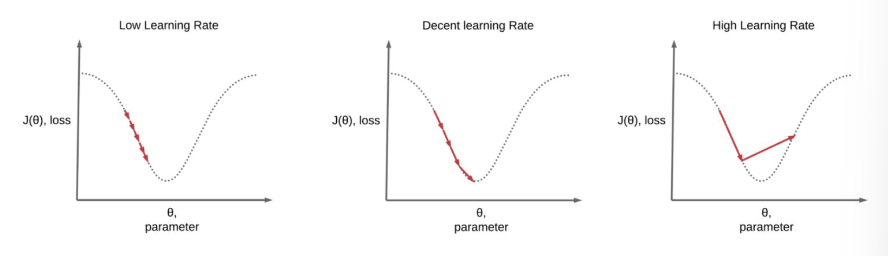 How do we choose a good learning rate then? This depends on the learning problem, the optimiser, the batch size (large batch = large learning rate, vice versa), and the stage of training (we can reduce as training progresses).
How do we choose a good learning rate then? This depends on the learning problem, the optimiser, the batch size (large batch = large learning rate, vice versa), and the stage of training (we can reduce as training progresses).