We have a few metrics for machine learning classification tasks. These are broadly useful for traditional statistical approaches as well as deep learning approaches.
Accuracy
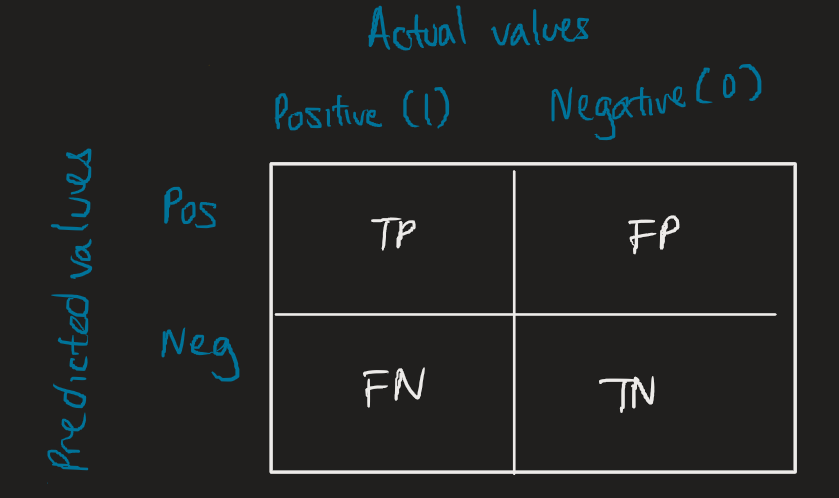
Confusion matrices help us assess how accurate our model is.
 The quantitative formula for accuracy is:
The quantitative formula for accuracy is:
How we can interpret training/validation accuracy:
- A low accuracy means our model is underfitting. This may be indicative of the data, the difficulty of the underlying problem, but often shows that our model isn’t complex enough and we need to scale it (in layers, or decision trees, etc.).
- An immediately high accuracy indicates our model has overcapacity and we can simplify the underlying architecture.
- If the validation accuracy lags the training accuracy significantly, then it’s likely overfitting on the training data.
Assessing our testing accuracy should be done after we’ve sufficiently tuned our hyperparameters. This judges whether our model performs well on completely unseen data.
Sometimes a higher accuracy isn’t necessarily indicative of an ideal model (based on what’s most important for the model to achieve). For example, if we were predicting the probability of cancer, and negative diagnoses proportionally far outweigh the positive diagnoses, and our model only assesses negatives, then our model would have a high accuracy but would be unsuitable for the task.
Precision and recall
Some other metrics include precision, which describes how many are correctly classified in the predictions:
And recall, which describes how often the model correctly identifies true positives from all positive instances predicted:
Other metrics
The support is how many of a given class occur in the model.
The F1-score (or F-measure) is the harmonic mean of the precision and recall of a classification model with the aim of indicating the reliability of the model. Both contribute equally to the store.
In code
For classification tasks, we can output key metrics with the classification_report(), imported from sklearn.metrics import classification_report.
This outputs the precision, recall, F1-score, and support of the classes. The first column lists down what classes belong to the metrics (for a binary classifier, we see two: 0 and 1), and the accuracies.